| 1 | Stáhněte si přes FTP z fileserveru pomocí účtu anonym soubor db05.zip a extrahujte jej tak, aby rozbalené soubory byly ve složce c:\temp\db05 | FileZilla |
| 2 | Otevřte v textovém editoru soubor thesaurus.sql a zjistěte jaké jsou sloupce tabulky | PSPad |
| 3 | Spusťte příkazový řádek a přejděte v něm do složky db05 | cmd, cd |
| 4 | Vytvořte ve složce db05 novou databázi db05.sqlite spuštěním: c:\programy\sqlite\sqlite3 db05.sqlite |
cmd |
| 5 | Vytvořte v db05 novou tabulku thesaurus s odpovídajícími sloupci | create table |
| 6 | Načtěte data ze souboru thesaurus.sql | .read |
| 7 | Přerušte načítání dat do databáze | sqlite3 |
| 8 | Otevřte znovu v textovém editoru soubor
thesaurus.sql a doplňte začátek a konec transakce BEGIN TRANSACTION; ... COMMIT; |
PSPad |
| 9 | Najděte a opravte chybu v názvu sloupce (viz chybové hlášení při .read), uložte soubor a zavřete PSPad | PSPad |
| 10 | Smažte v db05.sqlite tabulku thesaurus a poté ji znova nadefinujte | drop table, create table |
| 11 | Načtěte data ze souboru thesaurus.sql a porovnejte rychlost načtení, ověřte počet řádků v tabulce pomocí select count() ... | .read |
| 12 | Ověřte nastavení journalu příkazem pragma journal_mode; |
| 13 | Ověřte režim zamykání příkazem pragma locking_mode; | sqlite3 |
| 14 | Zamkněte databázi nastavením výhradního režimu pragma locking_mode=exclusive; | |
| 15 | Smažte první řádek tabulky thesaurus příkazem delete from ? where id=?; | |
| 16 | Otevřte další instanci příkazového řádku, spusťte v něm také sqlite3 s otevřením databáze db05.sqlite | cmd |
| 17 | V této druhé instanci zkuste smazat řádek tabulky thesaurus s id=2 | sqlite3 |
| 18 | Zavřete cmd okno, kde je hlášení o zamknuté databázi |
| 19 | Najděte v tabulce thesaurus synonyma pro slovo
'machine' uspořádaná abecedně: select ? from ? where ? order by ?; |
sqlite3 |
| 20 | Vypište slovní druhy (podst.jm., sloveso, ...) obsažené ve slovníku (každý druh může být uveden jen jednou) | |
| 21 | Vypište prvních 10 synonym (podle abecedy) a zapamatujte si rychlost výpisu | |
| 22 | Vypište synonymum s OFFSETEM 100000 a zapamatujte si rychlost výpisu |
| 23 | Vytvořte index pro sloupec word_eng: create index index_word_eng on thesaurus (word_eng); |
sqlite3 |
| 24 | Podobně vytvořte index_synonym pro synonyma | |
| 25 | Ověřte indexy ve schématu tabulky thesaurus | .schema |
| 26 | Ověřit indexy lze i příkazem .indices tabulka | .indices |
| 27 | Znovu vypište prvních 10 synonym (podle abecedy) a porovnejte rychlost | |
| 28 | Také vypište synonymum s OFFSETEM 100000 a porovnejte rychlost |
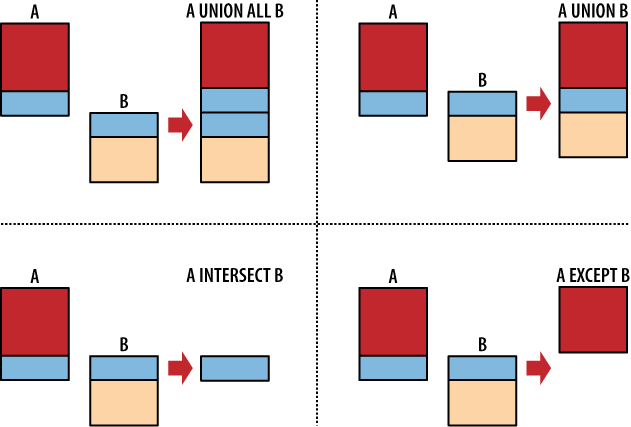
Operátory:
| 29 | Vytvořte v db05.sqlite novou tabulku pratele se sloupci id, jmeno, mesto, team (můžete použít vzor.sql) včetně indexu pro sloupec jmeno | PSPad, sqlite3 |
| 30 | Vložte do tabulky min. 3 řádky s různými daty | |
| 31 | Podobně vytvořte novou tabulku nepratele se stejnymi sloupci jako u tabulky pratele + jedním novým sloupcem alias, tabulku vyplňte min. 3 řádky s jinými daty než v tabulce pratele (pozor na jméno indexu - musí být jiné než existující) | |
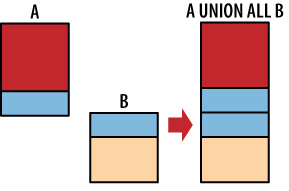
| 32 | Vypište najednou všechny existující týmy z obou tabulek: select team from pratele union select team from nepratele; |
|
| 33 | Předchozí příkaz upravte pro výpis seřazený podle abecedy: ... order by ... |
|
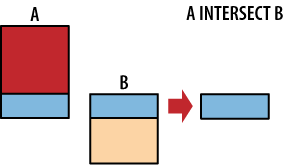
| 34 | Vypište města, kde máte přátele a zároveň nepřátele (operátor intersect) | |
| 35 | Poslední 3 příkazy vypište do souboru union.txt do složky db05 (.output union.txt) včetně použitého SQL příkazu (.echo on), názvu sloupce (.header on) | |
| 36 | Celou složku db05 zabalte jako db05.zip a uložte na fileserver | Filezilla |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}